new posts in all blogs
Viewing: Blog Posts Tagged with: googlebooks, Most Recent at Top [Help]
Results 1 - 15 of 15
How to use this Page
You are viewing the most recent posts tagged with the words: googlebooks in the JacketFlap blog reader. What is a tag? Think of a tag as a keyword or category label. Tags can both help you find posts on JacketFlap.com as well as provide an easy way for you to "remember" and classify posts for later recall. Try adding a tag yourself by clicking "Add a tag" below a post's header. Scroll down through the list of Recent Posts in the left column and click on a post title that sounds interesting. You can view all posts from a specific blog by clicking the Blog name in the right column, or you can click a 'More Posts from this Blog' link in any individual post.
“Jean Nepomucene Auguste Pichauld, Comte de Fortsas, was a man with a singular passion. He collected books of which only one copy was known to exist…. [W]hen he died on September 1, 1839 he possessed only fifty-two books, but each of them was absolutely unique. His heir, not sharing the old man’s passion for book collecting, arranged for an auction to sell off the library”
Compelling no? The auction really happened, the rest of it is made up, the creation of a local antiquarian, having a bit of a practical joke. Read more at blacksundae, or see the auction catalog, itself a rarity, on Google Books.
I’ve been scooting around a little bit lately and here are some things that have been crossing my virtual desk. I’ve also dealt with two wordpress issues [a hack! and an outdated sidebar navigation element] and I’ve upgraded to the latest version of WordPress. If you’re on a Summer schedule, I’d suggest upgrading before things get hectic.

By: Jessamyn West,
on 8/19/2009
Blog:
librarian.net
(
Login to Add to MyJacketFlap)
JacketFlap tags:
ala,
books,
copyright,
googlebooks,
google,
alaoitp,
copyrightadvisorynetwork,
financialtimes,
ft,
Add a tag
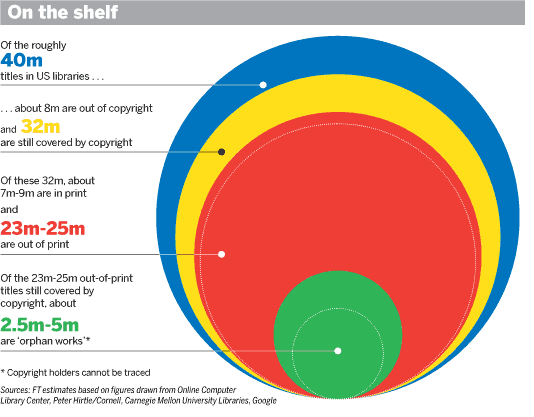
With the Google Books settlement coming up, a lot of people have been talking about copyright. I think this is generally speaking a really good thing. Here are some useful visualizations that may help you get your head around it.
- From the Financial Times is this article about what the Google business model could mean for out of print books and orphan works. According to their graphic [above] there are a lot of books wiht unclear status in US libraries that we should be concerned about.
- From ALA’s Copyright Advisory Network (a project of the Office of Information and Technology policy) comes a few helpful tools for looking at copyright as it pertains to libraries
Normally I’m not much of a joiner, but… “EFF is gathering a group of authors (or their heirs or assigns) who are concerned about the Google Book Search settlement and its effect on the privacy and anonymity of readers. This page provides basic information for authors and publishers who are considering whether to join our group.”
You can join too, if you’d like.
An ongoing debate in the copyright wars is whether an institution that is making reproductions of public domain materials available should be allowed to dictate terms (usually involving payment) for use of those items. We all know that libraries need money. It’s also true that having digital copies of rare materials available helps preserve the original items. So, if I want to download a public domain book from Google Books — say John Cotton Dana’s book A Library Primer — I get usage guidelines from Google attached to the pdf I’ve downloaded.
Usage guidelines
Google is proud to partner with libraries to digitize public domain materials and make them widely accessible. Public domain books belong to the public and we are merely their custodians. Nevertheless, this work is expensive, so in order to keep providing this resource, we have taken steps to prevent abuse by commercial parties, including placing technical restrictions on automated querying.
We also ask that you:
+ Make non-commercial use of the files We designed Google Book Search for use by individuals, and we request that you use these files for personal, non-commercial purposes.
+ Refrain from automated querying Do not send automated queries of any sort to Google’s system: If you are conducting research on machine translation, optical character recognition or other areas where access to a large amount of text is helpful, please contact us. We encourage the use of public domain materials for these purposes and may be able to help.
+ Maintain attribution The Google “watermark” you see on each file is essential for informing people about this project and helping them find additional materials through Google Book Search. Please do not remove it.
+ Keep it legal Whatever your use, remember that you are responsible for ensuring that what you are doing is legal. Do not assume that just because we believe a book is in the public domain for users in the United States, that the work is also in the public domain for users in other countries. Whether a book is still in copyright varies from country to country, and we can’t offer guidance on whether any specific use of any specific book is allowed. Please do not assume that a book’s appearance in Google Book Search means it can be used in any manner anywhere in the world. Copyright infringement liability can be quite severe.
These are all “suggestions” as near as I can tell. As with the Chicken Coupon fiasco of a few days ago, the implied threat that comes along with this item puts a bit of a damper on the joy that is the public domain. Bleh. We’ve seen other big corporations and libraries doing this as well.
However, this post is mostly to say “Yay” about Cornell’s decision to remove all restrictions on the use of its public domain reproductions. Here’s their press release about it and here is the web page with the new policy. What’s their reasoning? Well among other thigns it’s hard to support a misson of open access and at the same time go out of your way to make materials more difficult to get ahold of and interact with. You can see some of Cornell’s 70,000 public domain items at the Internet Archive.
I was lucky enough to catch Brewster Kahle talking with Amy Goodman on Democracy Now on my drive home from NJLA. I feel like I’m pretty up on what’s going on with Google and the Internet Archive and book scanning. What I didn’t know is how Google’s agreements with libraries are hindering the IA’s access, not because of the contracts, but just because of differing priorities. The video and transcript are now available online.
AMY GOODMAN: Explain what you mean when you say it’s not legally required. You mean in the contract, what they have with Google? And so, if Google was here, they’d say, “We didn’t say they couldn’t give it to Internet Archive. That’s their prerogative.”
BREWSTER KAHLE: Correct, that basically Google didn’t put it in their contract. Yet from a library’s perspective, why have a book scanned twice? It’s wear and tear on the books. If they think that—and they wouldn’t have signed it if they didn’t think that the Google thing was a good idea. But now that they’ve signed this with Google, they don’t want it scanned again. And this is a problem, because the books, even the out-of-copyright books, are locked up perpetually.
I’ve been reading more, typing less. My super-bloggy friends told me lat year sometime that a lot of their friends were blogging less and Twittering more. I was surprised to hear that since it hadn’t really trickled down to my neck of the woods yet, but lately it has. While I still stay on top of my RSS feeds, I suspect that I can only do that because people are blogging less. I don’t know if they’re twittering more, having babies, buying houses or doing something else. I know what I’ve been doing: reading.
I’ve also been travelling which is probably not a totally fun thing to read about [if I could delete everyone's tweets from airports, I would -- unless they're me looking for someone to hang out with when my flight has been delayed] but I go through periods of educating, followed by periods of learning, etc. I also made a resolution to myself for this year to write new talks (some similar slides okay, all similar slides against the rules) so when I give talks, they’re more work but also better, I think. I’ll be doing a 2.0 talk in upstate New York for NCLS and then a few talks at NJLA next week. Lots of writing, good stuff to pass on.
What’s been really on my mind lately is the Google Books settlement. I happen to be lucky that an old time friend of mine from the blogger days, James Grimmelmann, is one of the major players in the “explain this to everyone” field day that is going on. He’s also a keen legal mind and a great writer so it’s been a joy to read what he and others have been writing. Here are some links to essays that may help you understand things.
Library Journal has a thorough article reporting on the panel on the Google Books settlement that happened at Midwinter.
Mitch Freedman, past president of ALA, wondered about changes to the “free to all” ideology of libraries, asking whether Google would permit, as do other databases, site licenses for public libraries. [Google's Dan] Clancy said that, given the consumer market, there was no agreement on remote access, but that could change down the road. “Authors and publishers were not comfortable with remote access.” While Freedman said that issue was resolved with database publishers, Clancy responded that those publishers don’t have a model aimed at consumers. He noted that “the challenge of selling into this market is not Google’s core competence,” so consortial discounts are authorized in the agreement.
In light of the recent Google Books/APA settlement, Harvard has examined the details and decided not to be part of the project after all.
Harvard’s university-library director, Robert C. Darnton, wrote in a letter to the library staff, “the settlement provides no assurance that the prices charged for access will be reasonable, especially since the subscription services will have no real competitors [and] the scope of access to the digitized books is in various ways both limited and uncertain.” He also expressed concern about the quality of the scanned books, which “in many cases will be missing photographs, illustrations, and other pictorial works, which will reduce their utility for research.”
Update: According to the comments, I had this sort of wrong. Harvard is deciding to not have Google scan their copyrighted books but the digitzation project proceeds apace. Thanks Jon.
The Google Operating System blog has taught me how to do this…
[lisnews]
IN the days when furniture was defined as “that which may be carried about,” the natural bookcase was a chest with a strong lock. These chests, packed with precious manuscripts, followed the prince or noble from one castle to another, and were even carried after him into camp. Before the invention of printing, when twenty or thirty books formed an exceptionally large library, and many great personages were content with the possession of one volume, such ambulant bookcases were sufficient for the requirements of the most eager bibliophile.
I enjoyed Henry Petroski’s treatise on book shelving called The Book on the Book Shelf. I am also enjoying Edith Wharton’s 1897 chapter on a smilar topic. [thanks will!]
bookshelf,
bookshelves,
edithwharton,
google,
googlebooks
There was so much good stuff in the Carnival yesterday, that I didn’t append some of my favorite links from the week, but here they are.
- Two links about Google Books. One is Scott Boren’s long piece on LISNews about full txt serching in books. What you can search and how you can search it. Great well-researched piece. The second is Julia Tryon’s contribution to FreeGovInfo concerning the amount of government information available via Google Books. Google provides no statistics. This will be part of an ongoing project she’ll be working on there, stay tuned.
When looking at the search results in Google for publisher field has GPO, I found 141,600 items, only 82,487 of which were available in the full view. And although it is nice to think that we have the full text for 82,487 documents, not all of them can be used. I randomly picked a title to see how it looked and chose the Statistical Abstract for 1954. The pages were clear enough to read easily but on every even numbered page part of the right hand column was chopped off.
- Also from FreeGovInfo comes this analysis of Google Video’s closing and what happened to all those DRMed video files that people supposedly “purchased” Please read Part I: DRM Killed the Files and also Part II: Why the Google Video story should scare you.
- Karen Schneider has been writing some great stuff lately. It’s been fun to see her getting into what I see as the more technical side of librarianing because her explanations of techie stuff are clear and free of nonsense while still being readable and engaging. Her article in Library Journal Lots of Librarians Can Keep Stuff Safe about LOCKSS and Portico really helped me understand the fairly complicated world of e-journal archiving.
- Bryan Herzog’s always-excellent blog has pulled some Reader’s Advisory suggestions off of ME-LIBS the Maine Librarie dicussion list and added his own commentary. Brian also made a custom book review search using Google’s custom search function. Very very nice. I’d love to see someone toss together a page of Google Custom Searches that were useful to librarians. Has anyone done this? I’ve already made a Custom Ego Search but that’s not the same thing.
Despite my Very Large Skepticism of Google in general, the tool itself is very easy to set up and is potentially extremely useful (especially for librarians). Basically, it lets you limit searching to a select group of websites - in this case, book review websites
freegovinfo,
frl,
google,
googlebooks,
herzog,
linkdump
Google Books has an enormous amount of material. This is good. However, they paint copyright restrictions with a wide brush and err on the side of protecting copyright holders. So, most content on Google Books that has been published post-1923 are restricted (possibly all, but definitely most). This may or may not be good for most people, but it’s certainly bad in some specific instances, like with government documents. These are in the public domain and yet you can only see “snippets” on Google Books. Rick Prelinger described this phenomenon last year. The problem still exists. The concern, apparently is that cop[yrighted material may appear within these documents — hearings especially — and since Google can’t spare the humans to do the due diligence, we all suffer with restricted access. [freegovinfo]
copyright,
googlebooks,
govdocs
By: Jessamyn West,
on 1/29/2007
Blog:
librarian.net
(
Login to Add to MyJacketFlap)
JacketFlap tags:
flickr,
'puters,
me,
meta,
del.icio.us,
googlebooks,
machine tags,
mom,
superpatron,
Add a tag
I like books because they tend towards linearity and being one little knowledge parcel of something. However more and more when I read (latest book: Book of Lists, 90’s edition) I have a little index card that I use as a bookmark — card catalog card, actually — that I make notes on. The notes often turn into Google searches, del.icio.us links, MetaFilter posts and emails to my Mom. My books become more than themselves by being dissected and shared.
So, this has been the theme for this weekend, a weekend that had me teaching my Mom how to use Greasemonkey scripts to show more photos on her main Flickr page. I also taught her how to use Grab to do screen captures, how to take long shutter photos with her camera and why del.icio.us is considered “social.” She even discovered she had fans on del.icio.us, what fun! Three other things that sprang up, regarding the meta level of things.
- Flickr Machine Tags - tagging is great, but most people agree that some sort of structured taxonomy complementing a folksonomy is a stronger and more useful way to make information findable. Enter machine tags. Also known as “triple tags” they add an almost faceted layer of classification to Flickr, but still in a totally “roll your own” way. So, for example. I took a picture of my Mom. She is also a Flickr user. In the past, I could add a tag that said “Mom” or “Muffet” (her user name) but there would be no way to explicitly link her Flickr identity to the Flickr picture of her except with a clunky HTML link which makes sense to a human reader but isn’t super clear to a machine. If you check the picture I linked to, it has a new sort of tag flickr:user=muffet which you create just like a normal tag, but it has parts to it. Right now it’s the Wild West as far as what you can build into machine tags — see hoodie:color=orange there aren’t really any standards or even accepted practices, but there are a lot of people doing a lot of talking and it’s an exciting time to be into taxonomies.
- Ed “superpatron” Vielmetti and I have been sending del.icio.us mail this evening. This diagram should explain everything.
- Back to books for a second. How great would it be if, while you were reading a book, you could have a graphical representation of the places talked about? Well, one of the rocket scientists over at Google Book Search is building just that sort of tool. Their post Books:Mapped explains a little of how it works. The about page of the book on Google Books will have a map, if one is available. Here is an example from David Foster Wallace’s book The Girl With Curious Hair or perhaps more dramatically The Travels of Marco Polo.
del.icio.us,
flickr,
googlebooks,
machine tags,
me,
meta,
mom,
superpatron

[...] few late summer links [web link]librarian.net (26/Aug/2009)“…people have advice bernie margolis now the state [...]